关于 Flink checkpoint,都在这里(二)
coco在上一篇我们提到 Flink 基于 checkpoint 机制进行容错,保障了精确一次(exactly-once)语义。那么业界的其他分布式计算框架,如 spark streaming、storm 它们的容错思路与 Flink 相同吗?容错到底是在做什么呢?本篇将从更高的角度了解容错机制,深入理解容错的本质和核心思想。
#2 主流分布式实时计算框架是如何进行容错的?
目前业界主流的实时计算框架包括 Flink、Spark Streaming、Storm。相比于 Batch,Stream 的容错则需要考虑更多。Batch 数据通常基于稳定性较高的分布式存储进行数据的读写(如 HDFS、S3 等),当数据计算出现异常时可以通过重新计算的方式保证最终结果的一致性,Spark 就是基于这样的思路设计的,它通过 lineage 机制来重新计算。并且 Batch 计算往往不需要过多的考虑数据的时效性,而且不需要做到 7×24 小时的运行。但相对于 Stream 而言则会更加复杂。
对于 Stream 而言需要面对不同的流式数据源,可以是 File Stream、队列(如 Kafka),甚至可能是某个服务发来的消息。数据源的多样性就注定了 Stream 的容错需要重新进行考虑。并且 Stream 数据的容错需要在短时间内进行恢复,否则将可能会导致大量的数据积压甚至丢失,因为 Stream 数据链路不会因为下游处理任务的异常而停止数据的产出。
让我们将问题描述的更具体一些,方便更清楚的了解 Stream 的容错思想。对于分布式计算而言,目前主流的思路都是采用 Master-Slave 架构。Master 主要用于进行 Slave 节点的管理(比如检测 Slave 是否存活,状态管理等),Slave 主要是担当数据计算的职责。因此,从容错角度而言分为:
- Master 节点容错(如 Flink JobManager、Spark Streaming Driver)
- Slave 节点容错(如 Flink TaskManager、Spark Streaming Executor)
Master 节点容错
Master 容错相对而言较为简单,因为不需要直接参与数据计算。主要分为有状态的 Master 和无状态的 Master 两类。
像 Storm 这类无状态的实时计算框架,Master(即 Storm 的 Nimbus 节点)的异常往往不影响 Slave(即 Storm worker 节点)的数据计算,只需要重新启动一个 Master 即可,这个过程中不需要进行 Master 状态的恢复,也不会影响实时数据的处理。甚至 Slave 节点在无感知的情况下就完成了 Master 的恢复。但是这种方式会牺牲一定的功能,实时计算框架本身无法支持状态流的处理。
像 Flink、Spark Streaming 这类包含状态的实时计算框架,需要恢复 Master 节点的同时还需要对其状态进行恢复,Master 状态信息包含一些必要的配置、以及对 Slave 节点状态管理的信息(如“某个 Slave 节点的状态快照所在的 HDFS 路径”)。Spark Streaming、Flink 的做法都是基于 checkpoint 机制对 Master 节点的状态进行备份,异常发生时需要基于上一次的状态备份进行恢复。
Flink 还提供了 HA 机制,即同时运行至少 2 个 JobManager 节点,但是只有其中一个真正的处理管理事务(称为主节点——Leader),其他的仅仅保持状态信息的同步(称为从节点——Standby)。一旦 Leader 发生异常,其中一个 Standby 将会代替异常节点继续进行任务的管理。更多关于 Flink HA 可以参考官方文档。这种机制是牺牲更多的资源来换取任务的稳定性,主从切换的成本相比于从状态备份中恢复速度更快。
Slave 节点容错
Stream 数据处理整体而言可以分为 3 部分:
- 数据接收:从数据源获取数据,如 Flink Source
- 数据处理:对数据进行计算和处理,如 Flink Transform 算子
- 数据写入:将数据写入外部系统中,如 Flink Sink
根据不同的保障级别,Stream 数据容错级别又分为 3 种语义:
- at most once:最多一次,数据最多被处理一次,即允许数据的丢失
- at least once:最少一次,数据最少被处理一次,该语义要比 at most once 保障级别更高,因为它不允许数据丢失,但是数据可能发生重复
- exactly once:精确一次,即数据仅被处理一次。该语义是最高级别的语义,它不允许数据的丢失,也不允许数据被重复的处理
我们之所以将数据接收和写入单独拿出来,是因为在面对不同的数据源时,实时框架的容错机制与最高语义保障级别是不同的。如 Flink 而言,它的 exactly-once 语义总的来说是针对于数据处理阶段而言,即只有框架内数据的处理可以保障 exactly-once,而数据的接收、写入是否是 exactly-once 语义取决于数据源本身与 Source、Sink 算子的实现逻辑。通常来说,我们将能够保障数据接收、数据处理、数据接入整体数据一致性称为端到端(end-to-end)的数据一致性。
端到端的数据一致性保障相对而言是很复杂的,因为数据源的种类众多,这些一般都不是分布式实时框架中的一部分,数据的发送与接收逻辑不受实时框架的控制。
对于 Storm 而言,框架内仅提供了相关的接口用于用户自己实现一致性语义,并没有直接提供各种存储的一致性 Spouts,数据写入也是如此。数据处理过程提供 at-least-once 语义保障(exactly-once 语义由 Storm Trident 提供了保障,本篇暂不做讨论)。Storm 通过 ACK 的机制保证 at-least-once 语义。简单来说,当 Storm 接收到一条数据后将会给这条数据唯一的 id,数据被下游 Bolts 处理但是处理后的 id 不会发生改变,当且仅当该 id 的数据经过的 Bolts 全部 ACK 后才认定该数据被彻底处理(fully processed),否则 Spout 将再次发送该数据直到数据被彻底处理。
Spark Streaming 的数据接收通过预写入日志的机制保障了 at-least-once 语义。简单来说,就是将接收到的数据以日志的形式写入到稳定的存储中(存储位置基于 checkpoint 配置获取),这样一来就与数据源解耦,可以基于预写入日志实现数据重发的能力,从而保障 at-least-once 语义。数据处理过程中基于 RDD 的容错机制进行恢复,提供了精确一次的语义。数据写入需要用户自己实现,Spark Streaming 提供了两种思路:幂等写入和事务性写入。
Flink 全局基于 checkpoint 进行容错,通过向流数据中插入特殊的事件——checkpoint barrier 来触发各个算子制作状态快照,快照会写入到持久化的存储中。Flink Source、Sink 的语义保障需要依赖数据源以及自身的实现逻辑。但是 Flink 提供了多种状态接口,如 ListState、MapState,用于进行算子状态的记录,状态容错可以保障 exactly-once 语义。这也是与 Spark Streaming 的不同之处。
容错的本质和核心思想
到这里我们大致了解了各个框架的容错机制,我们不禁想回味一下:分布式实时计算框架的容错机制的本质是什么?容错到底在保障什么?
从本质上讲,容错在保障数据可以被正确的处理,即使在发生异常的情况下。实时流处理的正确性又体现在处理过程的完整性与时序的正确性。即一条数据要被所有的逻辑完整的处理一次(根据语义的不同也可能是多次),且多条数据之间的处理的时序不发生改变。
举个例子,如下图所示的数据流 DAG 图中,流数据序列 [1, 2, 3, …, n] 被输入到 A 中,然后最终流向 D。完整性即每一个事件都被完整的 DAG 路径处理,即 A -> B -> D 或 A -> C -> D,时序性即事件 1 永远先于事件 2 被处理,即使在发生了异常后恢复的情况下也是如此。
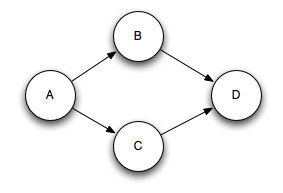
从整体来看,实时分布式计算框架的容错机制核心思想是确认与重试,但是不同的框架重试过程中回滚的数据量不同。
Storm 通过 ACK 机制判断数据是否完整处理,否则将重发数据,重新进行计算。这种单条数据粒度的 ACK 与重试机制即可以保障时序性,也可以保障处理过程的完整性。但是这样细的粒度牺牲了一定的性能。Storm 并没有将数据流进行冗余存储来保障容错,从这个角度而言它的容错是轻量级的。
Spark Streaming 通过微批次的方式将数据进行截断,以批次为单位进行容错。这种方式一旦发生了异常,可以从上一个批次中恢复继续执行。这种机制从一定程度上提升了性能,但是对时效性有损。因为微批次的思路对数据流进行了截断,时间语义上的单位时间也只能根据批次的大小来界定。Spark Streaming 提供了数据流的冗余(预写入日志)可以真正做到与数据源解耦,对于所有的数据源均可以保障容错的语义,但是这类的容错是重量级的。
Flink 的思路也是对数据进行截断,从而可以分段治之。相比于 Spark Streaming 而言这种截断并没有改变数据流的连续性,时间语义上的单位时间仍然是以事件粒度来界定。并且 Flink 不会对数据流进行冗余(虽然 unaligned-checkpoint 会产生一部分的数据冗余,但是与 Spark Streaming 这种全部数据冗余的思路是不同的),只关注计算中的状态容错。这种思路较为轻量级,并且能够保障 exactly-once 语义。但是这种思路无法应对所有的数据源场景,需要强依赖数据源的实现与 Source、Sink 算子的逻辑。
总结
| 框架 | 截断粒度 | 最高语义支持 | 端到端语义 |
|---|---|---|---|
| Storm | 单条数据 | at-least-once | 依赖数据源和算子具体实现 |
| Spark Streaming | 微批次数据,影响数据连续性 | at-least-once | at-least-once |
| Flink | 微批次数据,不影响数据连续性 | exactly-once | 依赖数据源和算子具体实现 |
总体而言,实时流的容错核心是基于数据截断和重试机制。Storm 的数据截断粒度是单条数据级别的,通过 ACK 的机制实现的重试机制,此截断粒度不会影响数据的时效性。Spark Streaming 的截断粒度是微批次的,截断会影响数据的时效性,然后通过数据冗余的方式保障了重试机制,这种冗余数据的方式可以面对任何数据源时都能够保证数据一致性。Flink 是基于 checkpoint barrier 将数据流截断,barrier 会随着数据流而流动,避免了流量截断带来的时效性影响,并且 Flink 容错只关注状态,借助状态的回滚来保证数据一致性。
从容错实现来看,三种框架的侧重点有所不同。Storm 作为无状态计算框架,采用的是非常简单有效的机制保障容错。Spark Streaming 更注重数据的可恢复性,希望通过备份原始数据能够在任何情况下、面对任何数据源都能够保证数据一致性。Flink 相对而言更加轻量,更注重数据的时效性,不希望容错机制带来太多的时效性损失(例如 unaligned-checkpoint)。
感谢你读到这里,希望你现在对 Flink 容错机制和其他的实时计算框架的容错机制有了一个基本的了解,对其容错思路和本质有了不同的想法。下一篇我们将讨论 Flink checkpoint 的数据结构,探索它究竟是如何存储的?都存储了哪些内容?基于这些备份数据如何在异常中恢复?